If you’re wondering why do I write about AWS that much, that’s because AWS is the cloud on which I spend most of my work hours in Skit.ai as a DevOps Engineer.
Ok, let’s take a look at what cluster autoscaler is and how does it work?
Definition
Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster when one of the following conditions is true:
- There are pods that failed to run in the cluster due to insufficient resources.
- There are nodes in the cluster that have been underutilized for an extended period of time and their pods can be placed on other existing nodes.
Documents
If you’re going to implement autoscaler in your EKS cluster, please read the FAQ .
The setting up of autoscaler in EKS is perfectly written by AWS document here
Once, things are set up, the logs should look like below :
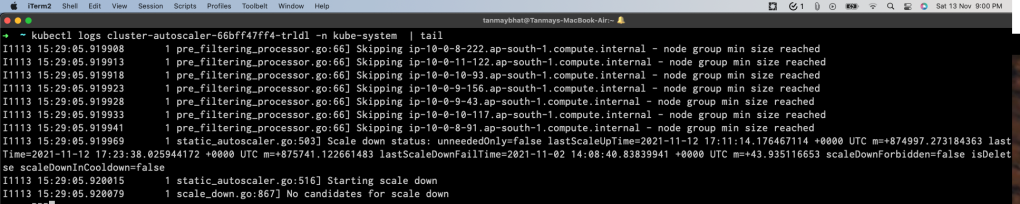
Now if you’re getting this, then it means the setup is clean. If we take a closer look at logs, it says node minimum size reached and cant scale down anymore.
Let’s understand scaling up and scale down criteria and it’s working.
Scale-down flow
Every 10 seconds (configurable by
--scan-intervalflag),Cluster Autoscaler checks which nodes are unneeded. A node is considered for removal when all below conditions hold:- The sum of cpu and memory requests of all pods running on this node is smaller than 50% of the node’s allocatable.
- All pods running on the node (except these that run on all nodes by default, like manifest-run pods or pods created by daemonsets) can be moved to other nodes.
- It doesn’t have scale-down disabled annotation (see How can I prevent Cluster Autoscaler from scaling down a particular node?)
If a node is unneeded for more than 10 minutes, it will be terminated.
Cluster Autoscaler terminates one non-empty node at a time to reduce the risk of creating new unschedulable pods.
The next node may possibly be terminated just after the first one, if it was also unneeded for more than 10 min and didn’t rely on the same nodes in simulation (see below example scenario), but not together. Empty nodes, on the other hand, can be terminated in bulk, up to 10 nodes at a time.
What happens when a non-empty node is terminated? As mentioned above, all pods should be migrated elsewhere.
Cluster Autoscaler does this by evicting them and tainting the node, so they aren’t scheduled there again.
Also, you should consider the below point :
- If there’s a node which is under-utilized but that node counts towards minimum node group size, then CA wont terminate that node and the logs will be similar to above screenshot.
Scale-up flow
- Scale-up creates a watch on the API server looking for all pods. It checks for any unschedulable pods every 10 seconds (configurable by
--scan-intervalflag). - A pod is unschedulable when the Kubernetes scheduler is unable to find a node that can accommodate the pod. For example, a pod can request more CPU that is available on any of the cluster nodes. Unschedulable pods are recognized by their PodCondition.
- Whenever a Kubernetes scheduler fails to find a place to run a pod, it sets “schedulable” PodCondition to false and reason to “unschedulable”.
- If there are any items in the unschedulable pods list, Cluster Autoscaler tries to find a new place to run them.
Testing the CA
- Let’s assume you got 2 t3.medium node and the min value of nodegroup is 2 with max value set to 5.< Run a nginx deployment with 500 replicas to see if cluster autoscaler scales up the nodes.. The command would be :
kubectl create deployment cluster-killer --image=nginx --replicas=500
- 2 nodes of that size can’t handle 500 pods of nginx, so they should be in pending state and CA scans for pending state pods every 10 seconds which should start couple of nodes within minutes.
- You can verify from command :
kubectl get node - Once all pods are scheduled, to test scale down, you can either delete the deployment using :
kubectl delete deployment cluster-killer
- Or scale down the replicas to zero with command :
kubectl scale deployment cluster-killer --replicas=0
- If you refer the logs of cluster autoscaler now, it will mention that X node is uneeded for X min etc.
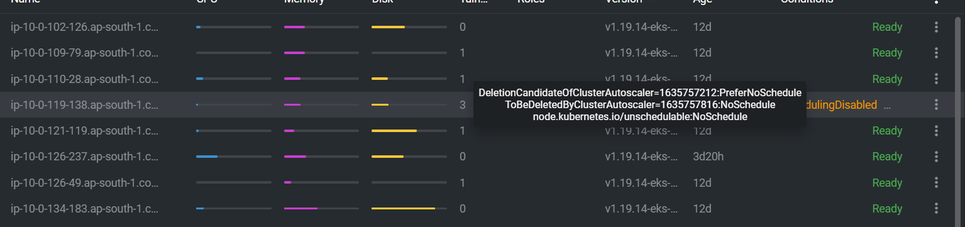
- The cool down period by default is 10 min so, after that time, it’ll apply taint on that node with name DeletionCandidateOfClusterAutoscaler and ToBeDeletedByClusterAutoscaler and removes the nodes. It looks like below: