As Kubernetes observability is going mainstream, it is important to understand and make an effort to reduce the cost of running these monitoring systems. One of the major costs in large scale clusters is the inter-AZ traffic. Whether using HA or not, vmagent scrapes metrics from all pods in the cluster, which are spread across multiple availability zones. This results in significant inter-AZ traffic that can become expensive.
Let’s imagine a scenario :
Cluster: 100 nodes × 100 pods/node = 10,000 pods.
Scrape Interval: 60 seconds.
Scrape Response Size: 50 KB.
AWS Region: us-west-2.
Inter-AZ Traffic Cost: $0.02/GB (AWS calculates data transfer costs for both incoming and outgoing data across different Availability Zones).
Assumption: Pods are evenly distributed across 3 AZs.
Inter-AZ Traffic Cost Breakdown
| Metric | Calculation | Value |
|---|---|---|
| Total Scrapes per Hour | 100 nodes × 100 pods × 60 minutes | 600,000 |
| Total Data Transferred per Hour | 600,000 scrapes × 50 KB | 28.61 GB |
| Inter-AZ Traffic per Hour | 28.61 GB × 2/3 | 19.07 GB |
| Cost per Hour | 19.07 GB × $0.02/GB | $0.38 |
| Cost per Day | $0.38 × 24 hours | $9.15 |
| Cost per Month | $9.15 × 30 days | $274.50 |
This is just for one cluster. If you have multiple clusters, then the cost can add up quickly.
High level solution
victoria-metrics supports global relabeling. This means that you can add relabeling configurations globally and it will be applied to all the scrape jobs. Let’s understand what relabeling is and how we can use it to reduce inter-AZ traffic.
There are three stages of relabeling in Prometheus:
- relabeling : This is done before the actual scrape is done. This is useful if you want to discard some targets before scraping.
- metric relabeling: This is done after the scrape is done and before the metrics are stored in the TSDB. This is useful if you want to modify the metric names or even drop some metrics.
- remote write relabeling: This is done before the metrics are sent to remote storage. This is useful if you want drop or modify metrics before sending to remote storage.
We will focus on the first stage of relabeling. When a target is discovered by vmagent, all the labels of the target are available to the relabeling configuration and in our case we will be using kubernetes_sd and hence all labels of a pod are available for relabeling with prefix __meta_kubernetes_pod_label_your_label_name.
The challenge is, there’s no direct way to get the availability zone of the node where the pod is running into the pod via labels. This is where Zonekeeper comes in. Zonekeeper is a kubernetes controller that adds (patches) availability zone label of a node where pod is running to the pod’s labels.
We will run one vmagent in each availability zone and configure the vmagent to scrape only the pods that are running in the same availability zone as the vmagent.
Zonekeeper
I wrote a tiny kubernetes controller called zonekeeper to do this. It’s a simple controller that watches pods and nodes and patches the pods with the availability zone label of the node where the pod is running.
Some of the code is taken from operator-sdk, which simplifies building Kubernetes controllers. The main logic is in below code snippet:
const (
podZoneLabel = "topology.kubernetes.io/zone"
)
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
logger := ctrl.Log.WithName("zonekeeper")
// Fetch the Pod
var pod corev1.Pod
if err := r.Get(ctx, req.NamespacedName, &pod); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// Skip if pod hasn't been scheduled yet
if pod.Spec.NodeName == "" {
logger.V(1).Info("Pod not yet scheduled")
return ctrl.Result{}, nil
}
// Fetch the Node for the Pod
var node corev1.Node
if err := r.Get(ctx, types.NamespacedName{Name: pod.Spec.NodeName}, &node); err != nil {
return ctrl.Result{}, fmt.Errorf("failed to get node %s: %w", pod.Spec.NodeName, err)
}
// Get zone from node labels
zone, exists := node.Labels[podZoneLabel]
if !exists {
logger.Error(nil, "node missing required zone label",
"node", node.Name,
"required_label", podZoneLabel)
return ctrl.Result{}, nil
}
// Check if update is needed because zone label might already be present
if pod.Labels[podZoneLabel] == zone {
logger.V(2).Info("pod zone label already up to date",
"pod", req.NamespacedName,
"zone", zone)
return ctrl.Result{}, nil
}
// if pod doesn't have labels, create a new map that stores labels
if pod.Labels == nil {
pod.Labels = make(map[string]string)
}
pod.Labels[podZoneLabel] = zone
// Create patch of original pod
podCopy := pod.DeepCopy()
logger.V(2).Info("updating pod zone label",
"pod", req.NamespacedName,
"zone", zone)
// Patch the pod object with the new zone label
if err := r.Patch(ctx, &pod, client.MergeFrom(podCopy)); err != nil {
return ctrl.Result{}, fmt.Errorf("failed to patch pod: %w", err)
}
// SetupWithManager sets up the controller with the Manager and filter only pods that are scheduled
func (r *PodReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&corev1.Pod{}).
WithEventFilter(predicate.NewPredicateFuncs(func(object client.Object) bool {
pod := object.(*corev1.Pod)
return pod.Spec.NodeName != ""
})).
Complete(r)
}
Running Zonekeeper
Running it inside a kubernetes cluster is simple. You can just apply the manifest file in the examples/zonekeeper directory.
kubectl apply -f examples/zonekeeper
Zonekeeper needs to have access to pods and nodes with list and patch permissions. These RBAC permissions are included in the manifest file.
Testing Zonekeeper
I have a simple kubernetes cluster with 6 nodes in us-west-2. I have deployed a simple metrics-exporter with 6 replicas with anti-affinity to spread the pods across the nodes.
Test pods can be deployed using the below command:
kubectl apply -f examples/test-pods
Once the pods are deployed, we can see that the pods are spread across the nodes in the cluster:
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metrics-exporter-59f4ddd48-5t6jq 1/1 Running 0 15h 10.42.3.4 k3d-multinode-agent-3 <none> <none>
metrics-exporter-59f4ddd48-74xt9 1/1 Running 0 15h 10.42.5.6 k3d-multinode-agent-5 <none> <none>
metrics-exporter-59f4ddd48-b6p9g 1/1 Running 0 15h 10.42.1.5 k3d-multinode-agent-1 <none> <none>
metrics-exporter-59f4ddd48-j2cbp 1/1 Running 0 15h 10.42.2.5 k3d-multinode-agent-2 <none> <none>
metrics-exporter-59f4ddd48-k6fkn 1/1 Running 0 15h 10.42.0.5 k3d-multinode-agent-0 <none> <none>
metrics-exporter-59f4ddd48-q4wtk 1/1 Running 0 15h 10.42.4.6 k3d-multinode-agent-4 <none> <none>
I’ve labeled the nodes with their respective availability zones:
kubectl label node k3d-multinode-agent-0 topology.kubernetes.io/zone=us-west-2a
kubectl label node k3d-multinode-agent-1 topology.kubernetes.io/zone=us-west-2b
kubectl label node k3d-multinode-agent-2 topology.kubernetes.io/zone=us-west-2c
#...
Once we start the controller, all the pods will have the availability zone label of the node where the pod is running :
│ 2025-01-06T05:17:22Z INFO zonekeeper Updating pod kube-system/svclb-traefik-685270de-q2dnf with zone label 'us-west-2b'
│ 2025-01-06T05:17:22Z INFO zonekeeper Updating pod monitoring/metrics-exporter-59f4ddd48-b6p9g with zone label 'us-west-2a'
│ 2025-01-06T05:17:22Z INFO zonekeeper Updating pod kube-system/helm-install-traefik-crd-2x99z with zone label 'us-west-2b'
│ 2025-01-06T05:17:22Z INFO zonekeeper Updating pod kube-system/traefik-d7c9c5778-4dkg9 with zone label 'us-west-2a'
...
Let’s create a vmagent which is a tiny prometheus compatible agent that can scrape metrics from pods and send to victoria-metrics server in the zone us-west-2a. We will configure the vmagent to scrape only the pods that are running in the same availability zone as the vmagent.
We want to apply the relabel config globally so that any PodMonitor or ServiceMonitor that exists or created will work without any changes.
Vmagent setup can be applied using the below command:
kubectl apply -f examples/vmagent
In config file of vmagent, we have added the below relabel config:
global:
scrape_interval: 60s
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_topology_kubernetes_io_zone]
action: keep
regex: us-west-2a
Any new PodMonitor or ServiceMonitor that exists will add a new scrape job below the global config and vmagent will append the relabel config to every scrape job (not directly, but it will be applied to every scrape job).
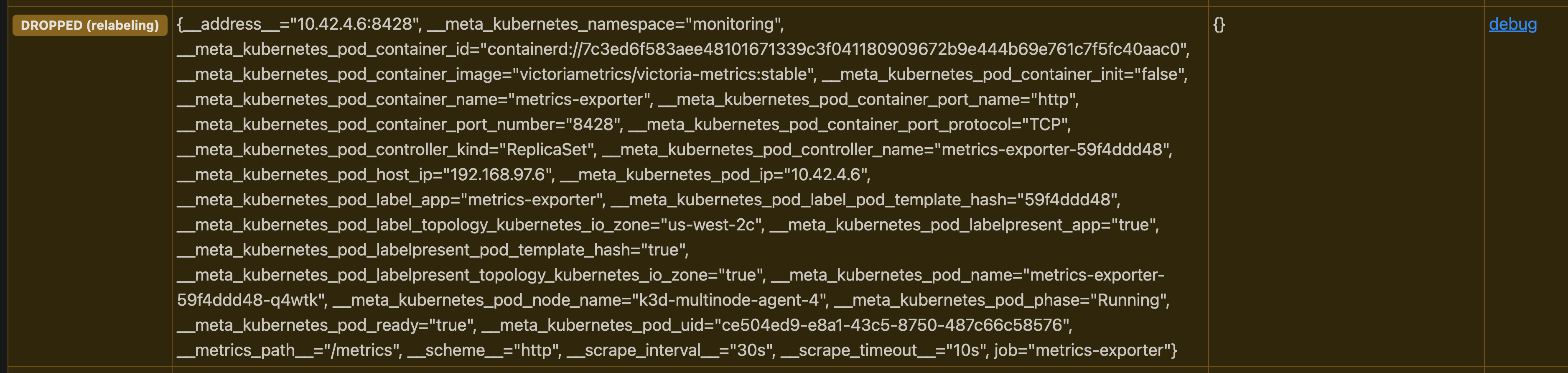
The below screenshot shows that the vmagent is scraping only the pods that are running in the same availability zone as the vmagent:

We can also see from service discovery that the pods from different availability zones are dropped :
Watching Multiple Namespaces
By default, zonekeeper watches all namespaces. If you want to watch only specific namespaces, you can update the WATCH_NAMESPACE environment variable in the deployment manifest file with the namespaces you want to watch, comma separated.
Filtering Pods based on Labels
Zonekeeper by default watches all pods. If you want to watch only specific pods based on labels, you can run zonekeeper with --pod-label-selector flag. This flag accepts multiple labels and values separated by comma. For example :
./zonekeeper --pod-label-selector=app=nginx,env=prod
Metrics
Zonekeeper exposes the below metrics on /metrics endpoint by default at port 8080 :
zonekeeper_label_updates_failed_total: The total number of pod label updates that failed.zonekeeper_label_updates_total: The total number of pod label updates that succeeded.zonekeeper_nodes_watched: The total number of nodes that are being watched by zonekeeper.zonekeeper_k8s_reconciliations_total: The total number of kubernetes reconciliations that have been performed by zonekeeper.
Zonekeeper vs Running Prometheus Agent as Daemonset
- The Prometheus Operator recently added support for running prometheus agent as daemonset. This is another good way to reduce inter-AZ traffic. But this means, we will be running another daemonset in every node and anyone running Kubernetes clusters at scale knows that DaemonSets can be expensive.
Prometheus Configuration Compatibility
- As of writing this blog, only VictoriaMetrics supports global relabeling. Prometheus doesn’t support global relabeling yet. But when it does, we can use the same relabel config in Prometheus as well.
References
- https://sdk.operatorframework.io/docs/building-operators/golang/quickstart/
- https://docs.victoriametrics.com/vmagent/
- https://github.com/VictoriaMetrics/VictoriaMetrics/issues/6966
- https://docs.victoriametrics.com/vmagent/#relabeling